File and I/O Management¶
The filesystem is one of the critical components to the service and users should aim to make best use of the resources. This chapter details the differing filesystems in use, the best practices for I/O, and basic housekeeping of your files.
Summary of available filesystems¶
| Directory | Explanation | Backed up? | Disk quotas | Files removed? |
|---|---|---|---|---|
| /home/<username>/ | User home directory** | Yes (hourly snapshots) | Yes (50GB) | No |
| /rds/user/<username>/hpc-work* | HPC work user directories** | No | Yes (1TB and 1 million files) | No automatic deletion currently |
| /local/ | Per-node local disk*** | No | Limited by partition size (57GB or 131GB) | Deleted after job completion |
| /ramdisks/ | Per-node tmpfs (in-memory)*** | No | Limited to 50% node RAM | Deleted after job completion |
| /usr/local/ | Cluster-wide software | Yes | N/A (not for user storage) | N/A (not for user storage) |
*For convenience, directories under /rds/user/<username>/ can be reached by symbolic links (shortcuts) of the same name under ~/rds.
**These are shared filesystems - files created on these are immediately visible to all nodes.
***These are private to each compute node - files created on these are destroyed after completion of the current job.
The /home directories are provided by an enterprise NFS storage system, whereas the /rds directories are provided by Lustre filesystems. The latter are performant and scalable, and it is on these that active data to be read or written by jobs should be placed (not under /home which is more suited to code, post processed results, reports etc).
The hpc-work directories provide free, 1TB storage for the personal use of Cambridge researchers. This storage cannot be shared with other users - please purchase shared storage from the Research Data Store (RDS). The hpc-work directories themselves are also provided by the RDS service. National Facility (DiRAC/Tier2/IRIS) users may already have additional project areas visible under /rds/user/<username> and ~/rds provided from pre-paid RDS storage which are shared between members of the same project.
Please note that for general users we currently provide two tiers only of non-transient storage (i.e. storage not limited to the runtime of a single job), namely /home and hpc-work (the latter possibly supplemented by additional RDS storage areas if purchased). As stated above RDS directories are based on Lustre and are the correct targets for job I/O. The term scratch space if encountered should be understood to refer to these Lustre storage areas.
Disk quotas¶
Each user has a limit on the amount of file storage he/she can use in the home directory, via quotas. Quotas on /home are currently set at 50 GB per user. Use the command quota to list your current usage - this reports for /home, /rds/user/<username>/hpc-work and any RDS projects you may have. A * symbol next to this value indicates that you have met or exceeded your quota (listed in GB under quota), and will need to reduce usage as soon as possible to below the quota value.
There are 1TB quotas in force on /rds/usr/<username>/hpc-work. For some filesystems, the limit value is slightly greater than the quota value (the former is also known as the hard limit, whereas the latter is the soft limit). It is possible (but not desirable) to exceed the soft limit, but not the hard limit. Exceeding the soft limit is allowed for 7 days, but if the over-quota condition is not corrected after 7 days, creation of new files and directories on the filesystem will become impossible. This happens immediately the soft limit is met if the hard and soft limits are equal. It is essential to resolve this situation as quickly as possible to prevent job errors and (in the case of /home) more subtle malfunctions of the account.
Additionally /rds/usr/<username>/hpc-work has a quota limit on the number of files that can be created, which is limited to 1 million files.
More RDS storage can be purchased - full details of this service are accessible here.
Backups¶
No backups are made of data in the RDS directories. Please view this in the same way as one uses Scratch on other systems
Snapshots of /home are being made hourly, daily and weekly. The snapshots are replicated to a second site, but note that the number retained falls off with time (for example the daily snapshots are retained for 2 weeks). Thus we cannot always retrieve deleted files (particularly short-lived files). Hence please be careful when deleting! If you need to retrieve a lost or damaged file, you should have the full pathname, and know, as closely as possible, when the file was damaged and when the file was created. Each directory has a hidden .snapshot subdirectory containing previous versions of data. Under these it is possible to search and browse for a good version of the file (which can be copied back to your home directory). For example,
/home/js123/workfiles/.snapshot/hourly_2022-07-06_18\:00/
contains an image of the /home/js123/workfiles directory as it was at 18:00 on 6th July 2022.
Interconnect¶
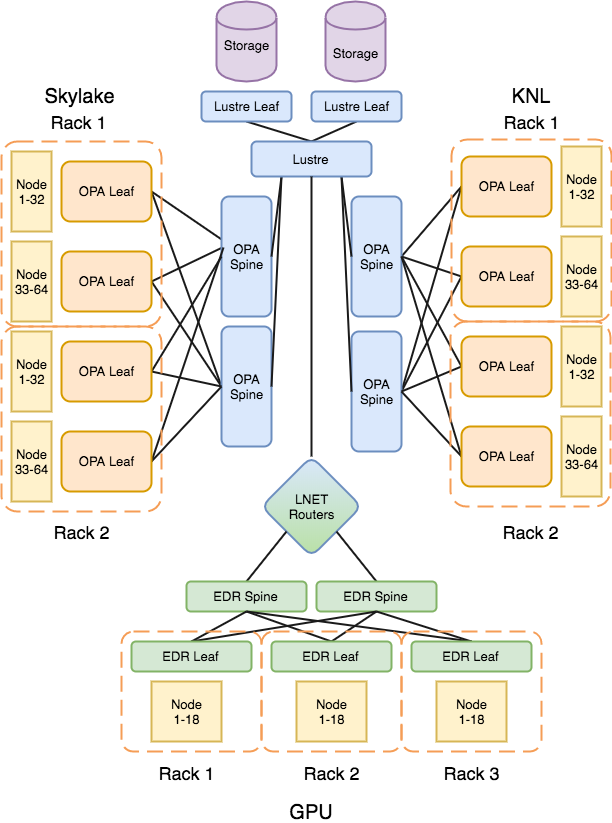
The CSD3 components are shown in the simplified topology diagram. Only a few of the racks within the system, however it should be noted from a networking point of view each rack is composed of two 32 node leaves. Within this nodes are non blocking. To speed between racks the network is 2:1 in oversubscription. The GPU system differs in interconnect and uses Infiniband EDR. This is similarly 2:1 in its oversubscription, with 18 nodes per leaf switch. The GPU system accesses the Lustre storage via I/O nodes using LNET. These LNET routers do not show any performance reduction in benchmarks run both direct from the OPA attached compute nodes and the GPU system.
File IO Performance Guidelines¶
RDS is build from 5 pools of 1PB Lustre. This helps when running the system for stability and flexibility. Each Lustre is made up of 24 OSTs. Object Storage Targets are the backend storage that your data is stored upon.
To make best use of this resource:
- Your home directory should not be used for I/O from running jobs. RDS is best placed to handle the load form multiple users writing large - size and volume - files to the file system.
- Striping: The default striping level on all Lustre filesystems in use at Cambridge is 1. This means that when writing your file it will only be written to one OST. While this dose not perform as well as larger striping sizes, it can be seen as a best case default. Should your I/O be more aggressive - file per process or different file sizes - a default stripe of 1 may be preferred. To get maximum performance out of the Lustre filesystem a stripe size of 24, would give you the maximum performance for a single large shared file.
- Whichever data formats you choose, it is vital that you test that you can access your data correctly on all the different systems where it is required. This testing should be done as early as possible in the software development or porting process (i.e. before you generate lots of data from expensive production runs), and should be repeated with every major software upgrade.
- Document the file formats and metadata of your important data files very carefully. The best documentation will include a copy of the relevant I/O subroutines from your code. Of course, this documentation must be kept up-to-date with any code modifications.
- Use binary (or unformatted) format for files that will only be used on the Intel system, e.g. for checkpointing files. This will give the best performance. Binary files may also be suitable for larger output data files, if they can be read correctly on other systems.
- Most codes will produce some human-readable (i.e. ASCII) files to provide some information on the progress and correctness of the calculation. Plan ahead when choosing format statements to allow for future code usage, e.g. larger problem sizes and processor counts.
- If the data you generate is widely shared within a large community, or if it must be archived for future reference, invest the time and effort to standardise on a suitable portable data format, such as netCDF or HDF.
File permissions and security¶
By default, each user is a member of the group with the same name as their username
on any of the services filesystems. You can changes this by setting the appropriate group using chown command.
The list of groups that a user is part of can be determined by running the groups command.
Permissions for files - read, write, execute(run or list directories) can be updated using the chmod command.
Never give more permission than is required for your files.
ASCII (or formatted) files¶
These are the most portable, but can be extremely inefficient to read and write. There is also the problem that if the formatting is not done correctly, the data may not be output to full precision (or to the subsequently required precision), resulting in inaccurate results when the data is used. Another common problem with formatted files is FORMAT statements that fail to provide an adequate range to accommodate future requirements, e.g. if we wish to output the total number of processors, NPROC, used by the application, the statement:
#Example Fortran
WRITE (*,'I3') NPROC
will not work correctly if NPROC is greater than 999.
Binary (or unformatted) files¶
These are much faster to read and write, especially if an entire array is read or written with a single READ or WRITE statement. However the files produced may not be readable on other systems.
- GNU compiler
-fconvert=swapcompiler option. - This compiler option often needs to be used together with a second
option
-frecord-marker, which specifies the length of record marker (extra bytes inserted before or after the actual data in the binary file) for unformatted files generated on a particular system. To read a binary file generated by a big-endian system on CSD3 systems, use-fconvert=swap -frecord-marker=4. Please note that due to the same ‘length of record marker’ reason, the unformatted files generated by GNU and other compilers on CSD3 systems are not compatible. In fact, the same WRITE statements would result in slightly larger files with GNU compiler. Therefore it is recommended to use the same compiler for your simulations and related pre- and post-processing jobs.
Other options for file formats include:
- Direct access files
- Fortran unformatted files with specified record lengths. These may be more portable between different systems than ordinary (i.e. sequential IO) unformatted files, with significantly better performance than formatted (or ASCII) files. The “endian” issue will, however, still be a potential problem.
- Portable data formats
These machine-independent formats for representing scientific data are specifically designed to enable the same data files to be used on a wide variety of different hardware and operating systems. The most common formats are:
It is important to note that these portable data formats are evolving standards, so make sure you are aware of which version of the standard/software you are using, and keep up-to-date with any backward-compatibility implications of each new release.